הבדלים בין גרסאות בדף "88-165 תשעב סמסטר ב/תקצירי הרצאות"
(←הרצאה חמישית) |
|||
| שורה 40: | שורה 40: | ||
טיפלנו ב'''התפלגות משותפת''' של זוג משתנים מקריים X,Y (המוגדרים על אותו מרחב הסתברות), שהיא הפונקציה המתאימה לכל a,b את ההסתברות <math>\ P(X=a,Y=b)</math>. מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים <math>\ P(X=a,Y=b) = P(X=a)P(Y=b)</math>. | טיפלנו ב'''התפלגות משותפת''' של זוג משתנים מקריים X,Y (המוגדרים על אותו מרחב הסתברות), שהיא הפונקציה המתאימה לכל a,b את ההסתברות <math>\ P(X=a,Y=b)</math>. מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים <math>\ P(X=a,Y=b) = P(X=a)P(Y=b)</math>. | ||
| + | |||
| + | === הרצאה שישית === | ||
| + | |||
| + | הגדרנו את ה[[תוחלת]] של משתנה מקרי - מעין ממוצע משוכלל (וגם משוקלל) של הערכים שהמשתנה יכול לקבל. אם הנקודות של המרחב הן בעלות אותה הסתברות ("התפלגות אחידה"), אז התוחלת שווה לממוצע של ערכי המשתנה. התוחלת היא הומוגנית (ממעלה ראשונה) ו[[פונקציה אדיטיבית|אדיטיבית]]: <math>\ E(X+Y)=E(X)+E(Y)</math>, וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב. | ||
| + | |||
| + | אם X,Y שני משתנים מקריים, X|Y=b (קרי "X בהנתן Y=b") הוא משתנה מקרי, שההתפלגות שלו תלויה בערך של b. אפשר לקצר ולומר ש-X|Y הוא משתנה מקרי, שההתפלגות שלו תלויה ב-Y. למשתנה הזה יש תוחלת, (E(X|Y, שהיא פונקציה של Y. הוכחנו את '''חוק התוחלת החוזרת''' <math>\ E(E(X|Y))=E(X)</math>. | ||
| + | |||
| + | === הרצאה שביעית === | ||
| + | |||
| + | כדי לנתח את התוחלת של מכפלות, הגדרנו את השונות המשותפת של שני משתנים: <math>\ Cov(X,Y) = E(XY)-E(X)E(Y)</math>. זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש- <math>\ E(XY)=E(E(XY|Y))=E(YE(X|Y))=E(YE(X))=E(X)E(Y)</math>, כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים '''בלתי מתואמים''' (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים). | ||
| + | |||
| + | ה'''שונות''' של משתנה מקרי X מוגדרת כשונות המשותפת שלו עם עצמו: <math>\ V(X)=Cov(X,X)=E(X^2)-E(X)^2=E((X-E(X))^2)</math>. זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות: <math>\ V(X)=V(E(X|Y))+E(V(X|Y))</math>. | ||
גרסה מ־00:16, 3 באפריל 2012
תקצירי הרצאות
תוכן עניינים
הרצאה ראשונה
(פרק 1, סעיף 1.2).
כל נתון סטטיסטי משמעותי אפשר לתאר על-ידי משתנים סטטיסטיים. נגענו קלות בטיפוסים של משתנים (משתנה איכותי, שבו אפשר רק לתאר את ההתפלגות; משתנה אורדינלי, שבו יש משמעות לסדר אבל לא לערך המספרי; משתנה אינטרוולי שבו יש משמעות גם להפרש המספרי, ומשתנה מנתי שבו יש בנוסף גם משמעות ליחס בין ערכים). דיברנו על הצגה גרפית של נתונים והנטיה הלא מוסברת של עורכי עיתונים להטעות באמצעותה.
למדנו כמה מדדי מרכז: ממוצע, שכיח, חציון, אמצע הטווח; וכמה מדדי פיזור: סטיית התקן, הטווח, הטווח הבין-רבעוני.
לצורך השוואה בין שני משתנים הצגנו את מקדם המתאם, שערכו תמיד בין 1 ל- 1-. כשהמשתנים בלתי תלויים, מקדם המתאם שלהם קרוב לאפס ("קרוב" ולא "שווה" משום שמדובר במדגם אקראי ולא באוכלוסיה כולה).
הרצאה שניה
(סעיף 1.3 - קומבינטוריקה).
מספר הדרכים לסדר n עצמים שונים בשורה הוא 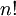 . מספר תת-הקבוצות של קבוצה בגודל n הוא
. מספר תת-הקבוצות של קבוצה בגודל n הוא 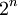 . מספר תת-הקבוצות בגודל k של קבוצה בגודל n הוא המקדם הבינומי n-מעל-k. זהו מספר הדרכים לבחור בלי החזרה, כשאין חשיבות לסדר. את המקדם הבינומי אפשר להכליל ל"מקדם מולטינומי", הסופר כמה דרכים יש לפרק קבוצה בגודל n לתת-קבוצות בגדלים
. מספר תת-הקבוצות בגודל k של קבוצה בגודל n הוא המקדם הבינומי n-מעל-k. זהו מספר הדרכים לבחור בלי החזרה, כשאין חשיבות לסדר. את המקדם הבינומי אפשר להכליל ל"מקדם מולטינומי", הסופר כמה דרכים יש לפרק קבוצה בגודל n לתת-קבוצות בגדלים 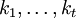 , כאשר סכום הגדלים שווה ל-n.
, כאשר סכום הגדלים שווה ל-n.
כשיש חשיבות לסדר, מספר הדרכים לבחור k עצמים עם החזרה, מתוך n, הוא החזקה 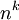 . מספר הדרכים לבחור בלי החזרה הוא
. מספר הדרכים לבחור בלי החזרה הוא 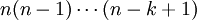 (מה קורה אם k>n?). מספר הדרכים לבחור k עצמים מתוך n, עם החזרה, כשאין חשיבות לסדר, שווה למספר הפתרונות החיוביים למשוואה
(מה קורה אם k>n?). מספר הדרכים לבחור k עצמים מתוך n, עם החזרה, כשאין חשיבות לסדר, שווה למספר הפתרונות החיוביים למשוואה 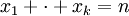 , שהוא המקדם הבינומי n+k-1 מעל n (זהו למעשה מספר ההתפלגויות האפשריות, עם x_i עצמים מסוג i).
, שהוא המקדם הבינומי n+k-1 מעל n (זהו למעשה מספר ההתפלגויות האפשריות, עם x_i עצמים מסוג i).
למדנו (והוכחנו) את עקרון ההכלה וההדחה, 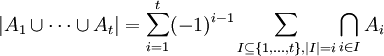 .
.
הרצאה שלישית
(סעיף 2.1 - מרחבי הסתברות בדידים)
הגדרנו: מרחב הסתברות הוא זוג סדור, הכולל את קבוצת המצבים (שהיא סופית או בת-מניה), ופונקציה מהקבוצה הזו למספרים הממשיים שסכום כל ערכיה הוא 1. תת-קבוצות של מרחב ההסתברות נקראות "מאורעות". את הפונקציה 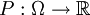 אפשר להמשיך לפונקציה
אפשר להמשיך לפונקציה 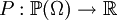 , המוגדרת על כל המאורעות. לערך
, המוגדרת על כל המאורעות. לערך 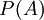 קוראים "ההסתברות של A". פונקציה זו מקיימת שתי תכונות חשובות: ההסתברות של המרחב כולו היא 1; וההסתברות של איחוד זר של מאורעות שווה לסכום ההסתברויות. את התכונה האחרונה הוכחנו במפורש, על-ידי חסימת ההפרש בין שני הסכומים בכל אפסילון חיובי.
קוראים "ההסתברות של A". פונקציה זו מקיימת שתי תכונות חשובות: ההסתברות של המרחב כולו היא 1; וההסתברות של איחוד זר של מאורעות שווה לסכום ההסתברויות. את התכונה האחרונה הוכחנו במפורש, על-ידי חסימת ההפרש בין שני הסכומים בכל אפסילון חיובי.
תרגמנו את עקרון ההכלה וההדחה לשפת ההסתברות.
הגדרנו הסתברות מותנית 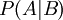 והוכחנו את נוסחת ההסתברות השלמה.
והוכחנו את נוסחת ההסתברות השלמה.
הרצאה רביעית
פתרנו את "בעיית המזכירה המבולבלת" בעזרת עקרון ההכלה וההדחה. הגדרנו מאורעות בלתי תלויים, והוכחנו כמה תכונות שקולות. הגדרנו אי-תלות משותפת של כמה מאורעות, והראינו שאי-תלות משותפת של שלושה מאורעות חזקה ממש מאי-תלות של כל זוג בנפרד.
הרצאה חמישית
הגדרנו משתנה מקרי, כפונקציה (כלשהי) ממרחב הסתברות בדיד (כלשהו) אל המספרים הממשיים. כדי לתאר משתנה מקרי X יש לדעת את ההתפלגות שלו, כלומר הפונקציה המתאימה לכל a את ההסתברות 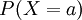 . ראינו שאם מפעילים פונקציה על משתנה מקרי, מתקבל משתנה מקרי חדש, שאפשר לחשב את ההתפלגות שלו מן ההתפלגות של המשתנה הראשון.
. ראינו שאם מפעילים פונקציה על משתנה מקרי, מתקבל משתנה מקרי חדש, שאפשר לחשב את ההתפלגות שלו מן ההתפלגות של המשתנה הראשון.
טיפלנו בהתפלגות משותפת של זוג משתנים מקריים X,Y (המוגדרים על אותו מרחב הסתברות), שהיא הפונקציה המתאימה לכל a,b את ההסתברות 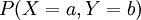 . מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים
. מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים 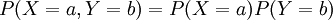 .
.
הרצאה שישית
הגדרנו את התוחלת של משתנה מקרי - מעין ממוצע משוכלל (וגם משוקלל) של הערכים שהמשתנה יכול לקבל. אם הנקודות של המרחב הן בעלות אותה הסתברות ("התפלגות אחידה"), אז התוחלת שווה לממוצע של ערכי המשתנה. התוחלת היא הומוגנית (ממעלה ראשונה) ואדיטיבית: 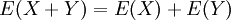 , וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב.
, וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב.
אם X,Y שני משתנים מקריים, X|Y=b (קרי "X בהנתן Y=b") הוא משתנה מקרי, שההתפלגות שלו תלויה בערך של b. אפשר לקצר ולומר ש-X|Y הוא משתנה מקרי, שההתפלגות שלו תלויה ב-Y. למשתנה הזה יש תוחלת, (E(X|Y, שהיא פונקציה של Y. הוכחנו את חוק התוחלת החוזרת 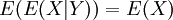 .
.
הרצאה שביעית
כדי לנתח את התוחלת של מכפלות, הגדרנו את השונות המשותפת של שני משתנים: 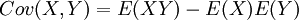 . זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש-
. זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש- 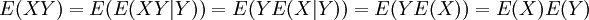 , כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים בלתי מתואמים (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים).
, כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים בלתי מתואמים (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים).
השונות של משתנה מקרי X מוגדרת כשונות המשותפת שלו עם עצמו: 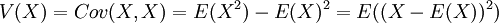 . זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות:
. זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות: 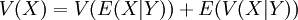 .
.