הבדלים בין גרסאות בדף "88-165 תשעב סמסטר ב/תקצירי הרצאות"
(←הרצאה עשירית) |
|||
| שורה 80: | שורה 80: | ||
=== הרצאה עשירית === | === הרצאה עשירית === | ||
| − | מעבר להתפלגויות הקלאסיות, חשוב לדעת גם לטפל בתופעות שבהן חישוב ישיר הוא מסובך או בלתי אפשרי, כדי לקבל קירוב להתנהגות שלהן. בחנו מקרוב את הדוגמא המפורסמת של "פרדוקס יום ההולדת": הסיכוי שבין 23 אנשים יהיו שניים שנולדו באותו יום בשנה הוא מעט יותר מחצי, למרות ש-23 "הרבה יותר קטן" מ-365. ההסבר הוא בחישוב הסיכוי לכך שאין התנגשויות בבחירה אקראית של ימי ההולדת: מתברר שהסיכוי הזה יורד בקצב קרוב ל- <math>\ exp(-\frac{n^2}{2K} | + | מעבר להתפלגויות הקלאסיות, חשוב לדעת גם לטפל בתופעות שבהן חישוב ישיר הוא מסובך או בלתי אפשרי, כדי לקבל קירוב להתנהגות שלהן. בחנו מקרוב את הדוגמא המפורסמת של "פרדוקס יום ההולדת": הסיכוי שבין 23 אנשים יהיו שניים שנולדו באותו יום בשנה הוא מעט יותר מחצי, למרות ש-23 "הרבה יותר קטן" מ-365. ההסבר הוא בחישוב הסיכוי לכך שאין התנגשויות בבחירה אקראית של ימי ההולדת: מתברר שהסיכוי הזה יורד בקצב קרוב ל- <math>\ exp(-\frac{n^2}{2K})</math> כאשר n הוא מספר האנשים (כאן 23) ו-K גודל המרחב שבו הם בוחרים. |
בדרך כלל קל יותר לחשב תוחלות מאשר הסתברויות (במיוחד אם מדובר במשתנה שאפשר לפרק לסכום של משתנים מציינים רבים). גם לגבי ימי הולדת, קל לחשב שתוחלת מספר ההתנגשויות (כלומר, זוגות של אנשים שנולדו באותו יום) היא <math>\ \frac{n(n-1)}{2K}</math>, כך שמספר ההתנגשויות עולה באופן ריבועי עם מספר האנשים, וכאשר n הוא מסדר הגודל של <math>\ \sqrt{K}</math> אפשר כבר לצפות להתנגשויות. דיברנו גם על המשתנה של זמן ההמתנה (להתנגשות הראשונה), שגם התוחלת שלו - שאותה לא חישבנו - פרופורציונלית לשורש גודל המרחב. | בדרך כלל קל יותר לחשב תוחלות מאשר הסתברויות (במיוחד אם מדובר במשתנה שאפשר לפרק לסכום של משתנים מציינים רבים). גם לגבי ימי הולדת, קל לחשב שתוחלת מספר ההתנגשויות (כלומר, זוגות של אנשים שנולדו באותו יום) היא <math>\ \frac{n(n-1)}{2K}</math>, כך שמספר ההתנגשויות עולה באופן ריבועי עם מספר האנשים, וכאשר n הוא מסדר הגודל של <math>\ \sqrt{K}</math> אפשר כבר לצפות להתנגשויות. דיברנו גם על המשתנה של זמן ההמתנה (להתנגשות הראשונה), שגם התוחלת שלו - שאותה לא חישבנו - פרופורציונלית לשורש גודל המרחב. | ||
| שורה 86: | שורה 86: | ||
את הנימוקים האלה אפשר להפוך על ראשם כדי להעריך את גודל המרחב (כשזה אינו ידוע). אם המחשב בוחר מספרים באקראי ואחרי 979 צעדים מופיע לראשונה אותו מספר בפעם השניה, סביר להעריך שגודל המרחב הוא כ- 979 בריבוע, היינו כמליון. | את הנימוקים האלה אפשר להפוך על ראשם כדי להעריך את גודל המרחב (כשזה אינו ידוע). אם המחשב בוחר מספרים באקראי ואחרי 979 צעדים מופיע לראשונה אותו מספר בפעם השניה, סביר להעריך שגודל המרחב הוא כ- 979 בריבוע, היינו כמליון. | ||
| − | טכניקת הפירוק לסכום של משתנים מציינים מאפשרת לתאר את המבנה של גרף מקרי (שבו יש n קודקודים, וכל אחת מ-n-מעל-2 הקשתות הפוטנציאליות מתממשת בהסתברות p, באופן בלתי תלוי). | + | טכניקת הפירוק לסכום של משתנים מציינים מאפשרת לתאר את המבנה של גרף מקרי (שבו יש n קודקודים, וכל אחת מ-n-מעל-2 הקשתות הפוטנציאליות מתממשת בהסתברות p, באופן בלתי תלוי). |
=== הרצאה אחת-עשרה === | === הרצאה אחת-עשרה === | ||
הכנה לרציף. | הכנה לרציף. | ||
גרסה מ־19:44, 1 במאי 2012
תקצירי הרצאות
תוכן עניינים
הרצאה ראשונה
(פרק 1, סעיף 1.2).
כל נתון סטטיסטי משמעותי אפשר לתאר על-ידי משתנים סטטיסטיים. נגענו קלות בטיפוסים של משתנים (משתנה איכותי, שבו אפשר רק לתאר את ההתפלגות; משתנה אורדינלי, שבו יש משמעות לסדר אבל לא לערך המספרי; משתנה אינטרוולי שבו יש משמעות גם להפרש המספרי, ומשתנה מנתי שבו יש בנוסף גם משמעות ליחס בין ערכים). דיברנו על הצגה גרפית של נתונים והנטיה הלא מוסברת של עורכי עיתונים להטעות באמצעותה.
למדנו כמה מדדי מרכז: ממוצע, שכיח, חציון, אמצע הטווח; וכמה מדדי פיזור: סטיית התקן, הטווח, הטווח הבין-רבעוני.
לצורך השוואה בין שני משתנים הצגנו את מקדם המתאם, שערכו תמיד בין 1 ל- 1-. כשהמשתנים בלתי תלויים, מקדם המתאם שלהם קרוב לאפס ("קרוב" ולא "שווה" משום שמדובר במדגם אקראי ולא באוכלוסיה כולה).
הרצאה שניה
(סעיף 1.3 - קומבינטוריקה).
מספר הדרכים לסדר n עצמים שונים בשורה הוא 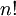 . מספר תת-הקבוצות של קבוצה בגודל n הוא
. מספר תת-הקבוצות של קבוצה בגודל n הוא 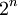 . מספר תת-הקבוצות בגודל k של קבוצה בגודל n הוא המקדם הבינומי n-מעל-k. זהו מספר הדרכים לבחור בלי החזרה, כשאין חשיבות לסדר. את המקדם הבינומי אפשר להכליל ל"מקדם מולטינומי", הסופר כמה דרכים יש לפרק קבוצה בגודל n לתת-קבוצות בגדלים
. מספר תת-הקבוצות בגודל k של קבוצה בגודל n הוא המקדם הבינומי n-מעל-k. זהו מספר הדרכים לבחור בלי החזרה, כשאין חשיבות לסדר. את המקדם הבינומי אפשר להכליל ל"מקדם מולטינומי", הסופר כמה דרכים יש לפרק קבוצה בגודל n לתת-קבוצות בגדלים 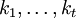 , כאשר סכום הגדלים שווה ל-n.
, כאשר סכום הגדלים שווה ל-n.
כשיש חשיבות לסדר, מספר הדרכים לבחור k עצמים עם החזרה, מתוך n, הוא החזקה 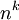 . מספר הדרכים לבחור בלי החזרה הוא
. מספר הדרכים לבחור בלי החזרה הוא 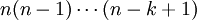 (מה קורה אם k>n?). מספר הדרכים לבחור k עצמים מתוך n, עם החזרה, כשאין חשיבות לסדר, שווה למספר הפתרונות החיוביים למשוואה
(מה קורה אם k>n?). מספר הדרכים לבחור k עצמים מתוך n, עם החזרה, כשאין חשיבות לסדר, שווה למספר הפתרונות החיוביים למשוואה 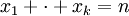 , שהוא המקדם הבינומי n+k-1 מעל n (זהו למעשה מספר ההתפלגויות האפשריות, עם x_i עצמים מסוג i).
, שהוא המקדם הבינומי n+k-1 מעל n (זהו למעשה מספר ההתפלגויות האפשריות, עם x_i עצמים מסוג i).
למדנו (והוכחנו) את עקרון ההכלה וההדחה, 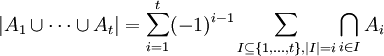 .
.
הרצאה שלישית
(סעיף 2.1 - מרחבי הסתברות בדידים)
הגדרנו: מרחב הסתברות הוא זוג סדור, הכולל את קבוצת המצבים (שהיא סופית או בת-מניה), ופונקציה מהקבוצה הזו למספרים הממשיים שסכום כל ערכיה הוא 1. תת-קבוצות של מרחב ההסתברות נקראות "מאורעות". את הפונקציה 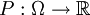 אפשר להמשיך לפונקציה
אפשר להמשיך לפונקציה 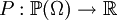 , המוגדרת על כל המאורעות. לערך
, המוגדרת על כל המאורעות. לערך 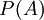 קוראים "ההסתברות של A". פונקציה זו מקיימת שתי תכונות חשובות: ההסתברות של המרחב כולו היא 1; וההסתברות של איחוד זר של מאורעות שווה לסכום ההסתברויות. את התכונה האחרונה הוכחנו במפורש, על-ידי חסימת ההפרש בין שני הסכומים בכל אפסילון חיובי.
קוראים "ההסתברות של A". פונקציה זו מקיימת שתי תכונות חשובות: ההסתברות של המרחב כולו היא 1; וההסתברות של איחוד זר של מאורעות שווה לסכום ההסתברויות. את התכונה האחרונה הוכחנו במפורש, על-ידי חסימת ההפרש בין שני הסכומים בכל אפסילון חיובי.
תרגמנו את עקרון ההכלה וההדחה לשפת ההסתברות.
הגדרנו הסתברות מותנית 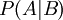 והוכחנו את נוסחת ההסתברות השלמה.
והוכחנו את נוסחת ההסתברות השלמה.
הרצאה רביעית
פתרנו את "בעיית המזכירה המבולבלת" בעזרת עקרון ההכלה וההדחה. הגדרנו מאורעות בלתי תלויים, והוכחנו כמה תכונות שקולות. הגדרנו אי-תלות משותפת של כמה מאורעות, והראינו שאי-תלות משותפת של שלושה מאורעות חזקה ממש מאי-תלות של כל זוג בנפרד.
הרצאה חמישית
הגדרנו משתנה מקרי, כפונקציה (כלשהי) ממרחב הסתברות בדיד (כלשהו) אל המספרים הממשיים. כדי לתאר משתנה מקרי X יש לדעת את ההתפלגות שלו, כלומר הפונקציה המתאימה לכל a את ההסתברות 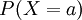 . ראינו שאם מפעילים פונקציה על משתנה מקרי, מתקבל משתנה מקרי חדש, שאפשר לחשב את ההתפלגות שלו מן ההתפלגות של המשתנה הראשון.
. ראינו שאם מפעילים פונקציה על משתנה מקרי, מתקבל משתנה מקרי חדש, שאפשר לחשב את ההתפלגות שלו מן ההתפלגות של המשתנה הראשון.
טיפלנו בהתפלגות משותפת של זוג משתנים מקריים X,Y (המוגדרים על אותו מרחב הסתברות), שהיא הפונקציה המתאימה לכל a,b את ההסתברות 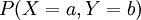 . מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים
. מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים 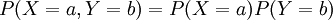 .
.
הרצאה שישית
הגדרנו את התוחלת של משתנה מקרי - מעין ממוצע משוכלל (וגם משוקלל) של הערכים שהמשתנה יכול לקבל. אם הנקודות של המרחב הן בעלות אותה הסתברות ("התפלגות אחידה"), אז התוחלת שווה לממוצע של ערכי המשתנה. התוחלת היא הומוגנית (ממעלה ראשונה) ואדיטיבית: 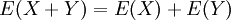 , וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב.
, וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב.
אם X,Y שני משתנים מקריים, X|Y=b (קרי "X בהנתן Y=b") הוא משתנה מקרי, שההתפלגות שלו תלויה בערך של b. אפשר לקצר ולומר ש-X|Y הוא משתנה מקרי, שההתפלגות שלו תלויה ב-Y. למשתנה הזה יש תוחלת, (E(X|Y, שהיא פונקציה של Y. הוכחנו את חוק התוחלת החוזרת 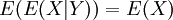 .
.
הרצאה שביעית
כדי לנתח את התוחלת של מכפלות, הגדרנו את השונות המשותפת של שני משתנים: 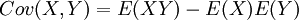 . זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש-
. זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש- 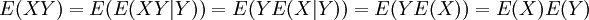 , כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים בלתי מתואמים (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים).
, כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים בלתי מתואמים (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים).
השונות של משתנה מקרי X מוגדרת כשונות המשותפת שלו עם עצמו: 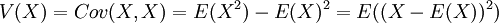 . זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות:
. זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות: 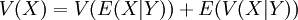 .
.
הרצאה שמינית
למדנו את ההתפלגויות (הבדידות) הקלאסיות:
- ההתפלגות האחידה על המספרים
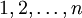 , שאותה מסמנים בסימון
, שאותה מסמנים בסימון ![\ X \sim U[1,n]](/images/math/3/f/b/3fbc5aa1e358398249771be7e3339344.png) . למשל, הערך שמתקבל מזריקת קוביה הוגנת מתפלג
. למשל, הערך שמתקבל מזריקת קוביה הוגנת מתפלג ![\ U[1,6]](/images/math/b/f/1/bf1f0b5d091d01510b6aa53865af36fc.png) , ואילו ספרה אקראית X מקיימת
, ואילו ספרה אקראית X מקיימת ![\ X+1 \sim U[1,10]](/images/math/c/4/1/c41326780473cdbb40d7800b5ebde73f.png) . התוחלת של משתנה כזה היא
. התוחלת של משתנה כזה היא 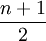 , והשונות
, והשונות 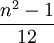 .
. - התפלגות ברנולי:
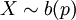 , שבה X מקבל רק את הערכים 0 (בהסתברות q=1-p) או p. התוחלת שווה לפרמטר p, והשונות היא pq. כל משתנה מקרי המקבל רק שני ערכים אפשר להביא (על-ידי העתקה לינארית) לצורה כזו. לדוגמא, אם X מקבל את הערכים אחד ומינוס אחד, אז
, שבה X מקבל רק את הערכים 0 (בהסתברות q=1-p) או p. התוחלת שווה לפרמטר p, והשונות היא pq. כל משתנה מקרי המקבל רק שני ערכים אפשר להביא (על-ידי העתקה לינארית) לצורה כזו. לדוגמא, אם X מקבל את הערכים אחד ומינוס אחד, אז 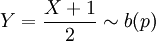 עבור p מתאים.
עבור p מתאים. - התפלגות בינומית:
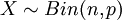 היא ההתפלגות של המשתנה הסופר כמה הצלחות יש בסדרה של n "ניסויי ברנולי" (ניסויים בלתי תלויים, שהסיכוי להצלחה בכל אחד מהם הוא קבוע, p). התוחלת של משתנה כזה היא np, והשונות npq (ההוכחה הקלה ביותר היא דרך משתנים מציינים).
היא ההתפלגות של המשתנה הסופר כמה הצלחות יש בסדרה של n "ניסויי ברנולי" (ניסויים בלתי תלויים, שהסיכוי להצלחה בכל אחד מהם הוא קבוע, p). התוחלת של משתנה כזה היא np, והשונות npq (ההוכחה הקלה ביותר היא דרך משתנים מציינים). - התפלגות פואסון:
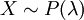 , המוגדרת כך ש-
, המוגדרת כך ש-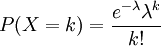 . התוחלת והשונות הן
. התוחלת והשונות הן 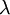 . התפלגות זו מופיעה כקירוב להתפלגות בינומית (אם , ו-n גדול, אז בקירוב טוב
. התפלגות זו מופיעה כקירוב להתפלגות בינומית (אם , ו-n גדול, אז בקירוב טוב 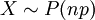 ), וגם בספירת תופעות לאורך זמן. את עניין ספירת התופעות לאורך זמן נסביר כשנלמד את ההתפלגות המעריכית (הרציפה).
), וגם בספירת תופעות לאורך זמן. את עניין ספירת התופעות לאורך זמן נסביר כשנלמד את ההתפלגות המעריכית (הרציפה). - התפלגות גאומטרית:
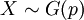 היא ההתפלגות של מספר הניסויים שיש לערוך עד להצלחה ראשונה (בסדרה של ניסויי ברנולי). הערך של משתנה זה אינו חסום, אם כי ההסתברות לערכים גדולים הולכת ודועכת (בקצב מעריכי). ההתפלגות הגאומטרית מיוחדת בתכונת חוסר הזכרון שלה: הידיעה שכבר נכשלו k ניסויים אינה מקרבת (ואינה מרחיקה) את ההצלחה הראשונה שתבוא.
היא ההתפלגות של מספר הניסויים שיש לערוך עד להצלחה ראשונה (בסדרה של ניסויי ברנולי). הערך של משתנה זה אינו חסום, אם כי ההסתברות לערכים גדולים הולכת ודועכת (בקצב מעריכי). ההתפלגות הגאומטרית מיוחדת בתכונת חוסר הזכרון שלה: הידיעה שכבר נכשלו k ניסויים אינה מקרבת (ואינה מרחיקה) את ההצלחה הראשונה שתבוא. - התפלגות "בינומית שלילית": מספר הניסויים שאפשר לבצע (בסדרת ניסויי ברנולי) עד לכשלון ה-k. הפרמטרים הם k וההסתברות הקבועה, p.
- התפלגות היפרגאומטרית: ההתפלגות של מספר הכדורים האדומים שמתקבלים כשמוציאים n כדורים (ללא החזרה!) מכד שבו A כדורים אדומים ו-B כדורים כחולים.
הרצאה תשיעית
בין ההתפלגויות השונות יש קשרים רבים, גם מעבר למובן מאליו (משתנה בינומי מוגדר כסכום של n משתנים מקריים ברנוליים בלתי-תלויים; משתנה "בינומי שלילי" אפשר להגדיר כסכום של משתנים מקריים גאומטריים). למשל:
- אם X,Y משתנים בינומיים בלתי תלויים עם אותו p (אבל n-ים שונים), אז X+Y בינומי (עם אותו p), משום שהוא סופר את כל ההצלחות בסדרה ראשונה ואחר-כך בסדרה שניה של ניסויים.
- אם X,Y משתני פואסון ב"ת, סכומם פואסוני (עם תוחלת השווה לסכום התוחלות, מה שאפשר לתרגם לחישוב הפרמטר, שהוא סכום הפרמטרים של X,Y).
- במקרה הקודם, ההתפלגות של X בהנתן X+Y היא בינומית.
- אם N הוא מספר ההתפרקויות של חלקיקים רדיואקטיביים במבחנה לאורך 25 דקות (משתנה פואסוני), ו-X הוא מספר ההתפרקויות שבהן התוצרים פגעו בלוחית המדידה (תופעה שהסיכוי לה הוא p, כלומר X בהנתן N מתפלג בינומית), אז X הוא משתנה פואסוני.
- אם X,Y משתנים מקריים גאומטריים, אז ההתפלגות של X בהנתן X=Y היא עדיין גאומטרית (הראו כמה קל למצוא את הפרמטר אם העובדה הזו על התפלגות X בהנתן X=Y ידועה!)
דוגמאות חשובות אחרות מתקבלות משאיפה לגבול.
- כאשר X מתפלג בינומית ו-n גדל תוך שהמכפלה np נשארת קבועה, ההתפלגות הולכת ומתקרבת להתפלגות פואסון עם הפרמטר np.
- בהתפלגות היפרגאומטרית, אם מגדילים את A,B תוך שמירה על היחס A:B, התהליך הולך ונעשה דומה לדגימה עם החזרה (משום שכשיש בכד המוני כדורים, ממילא הסיכוי לחזרה על אותו כדור הוא זניח), ואז המשתנה ההיפרגאומטרי נעשה בקירוב בינומי.
הרצאה עשירית
מעבר להתפלגויות הקלאסיות, חשוב לדעת גם לטפל בתופעות שבהן חישוב ישיר הוא מסובך או בלתי אפשרי, כדי לקבל קירוב להתנהגות שלהן. בחנו מקרוב את הדוגמא המפורסמת של "פרדוקס יום ההולדת": הסיכוי שבין 23 אנשים יהיו שניים שנולדו באותו יום בשנה הוא מעט יותר מחצי, למרות ש-23 "הרבה יותר קטן" מ-365. ההסבר הוא בחישוב הסיכוי לכך שאין התנגשויות בבחירה אקראית של ימי ההולדת: מתברר שהסיכוי הזה יורד בקצב קרוב ל- 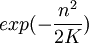 כאשר n הוא מספר האנשים (כאן 23) ו-K גודל המרחב שבו הם בוחרים.
כאשר n הוא מספר האנשים (כאן 23) ו-K גודל המרחב שבו הם בוחרים.
בדרך כלל קל יותר לחשב תוחלות מאשר הסתברויות (במיוחד אם מדובר במשתנה שאפשר לפרק לסכום של משתנים מציינים רבים). גם לגבי ימי הולדת, קל לחשב שתוחלת מספר ההתנגשויות (כלומר, זוגות של אנשים שנולדו באותו יום) היא 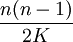 , כך שמספר ההתנגשויות עולה באופן ריבועי עם מספר האנשים, וכאשר n הוא מסדר הגודל של
, כך שמספר ההתנגשויות עולה באופן ריבועי עם מספר האנשים, וכאשר n הוא מסדר הגודל של 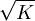 אפשר כבר לצפות להתנגשויות. דיברנו גם על המשתנה של זמן ההמתנה (להתנגשות הראשונה), שגם התוחלת שלו - שאותה לא חישבנו - פרופורציונלית לשורש גודל המרחב.
אפשר כבר לצפות להתנגשויות. דיברנו גם על המשתנה של זמן ההמתנה (להתנגשות הראשונה), שגם התוחלת שלו - שאותה לא חישבנו - פרופורציונלית לשורש גודל המרחב.
את הנימוקים האלה אפשר להפוך על ראשם כדי להעריך את גודל המרחב (כשזה אינו ידוע). אם המחשב בוחר מספרים באקראי ואחרי 979 צעדים מופיע לראשונה אותו מספר בפעם השניה, סביר להעריך שגודל המרחב הוא כ- 979 בריבוע, היינו כמליון.
טכניקת הפירוק לסכום של משתנים מציינים מאפשרת לתאר את המבנה של גרף מקרי (שבו יש n קודקודים, וכל אחת מ-n-מעל-2 הקשתות הפוטנציאליות מתממשת בהסתברות p, באופן בלתי תלוי).
הרצאה אחת-עשרה
הכנה לרציף.